
3 mins
OpenContent Silos
2 mins
In a computing context, cache refers to the temporary storing of data, usually for purposes of fast retrieval upon a second load. In search specifically, “cache” is a reference to a web cache, usually HTML pages and images that are stored either by the browser or the search engine to reduce bandwidth.
31 January 2023

When you visit a website, most browsers will retain some of the information on that website to enable it to load faster when you return to that page. The information is “cached” by the browser.
You may have been asked by a web designer to do a forced or “hard” refresh after they have made a change on your website that you can’t yet see in your browser.
This is because your cache is holding on to the older elements from that page and needs to be flushed out for the updates to show. This is known as “clearing the cache”.
Google, as well as other search engines, also keep cached copies of web pages for much the same reason browsers do: To enable faster processing and loading of data.
When a Google crawler visits a website, it retrieves web content and stores that in its cache. In this way, Google builds up a copy of all the web pages it visits on its own server. This is the Google cache.
Any searches that are performed on Google are effectively performed inside this cached version of the web stored on Google’s own server.
The cached version of your own web page can be viewed by clicking on the down arrow right next to the URL on the results page. This will take you to the cached version of that page. The time stamp at the top indicates when last a crawler visited that page:
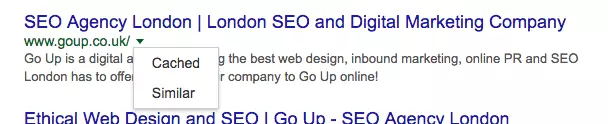
Clicking on “Cached” in the dropdown reveals a page with a banner similar to this one indicating the date the page was last visited by Google:

The cache also explains why updates to pages aren’t always immediately visible in search. A change to a title tag for instance, though implemented on a page, will only reflect once Google’s been back to the page and has updated its cached copy.
Web caching, aside from improving user experience through reduced load speed, also gives us a unique portal to the past.
The Internet Archive, a San Francisco-based nonprofit has been keeping copies of known websites in its archive since 1996.
Head over the The Wayback Machine at web.archive.org to have a look.
Apart from making for great fun revisiting old websites (see Apples website in 2000), this is also a very valuable tool for online marketing, helping SEO teams recover lost data and understand past trends.

